Canopy vs. Amazon Scraping APIs
Managed scraping APIs save time and cut maintenance; custom Amazon scrapers add flexibility but bring high costs and constant upkeep.

Canopy vs. Amazon Scraping APIs
Looking to access Amazon product data? You have two main options: use a managed solution like Canopy API or build your own scraper. Canopy API simplifies the process by offering ready-to-use REST and GraphQL endpoints for over 350 million products, saving you time and effort. In contrast, building custom scrapers involves significant technical challenges, like bypassing Amazon’s anti-scraping defenses and maintaining infrastructure.
Key Takeaways:
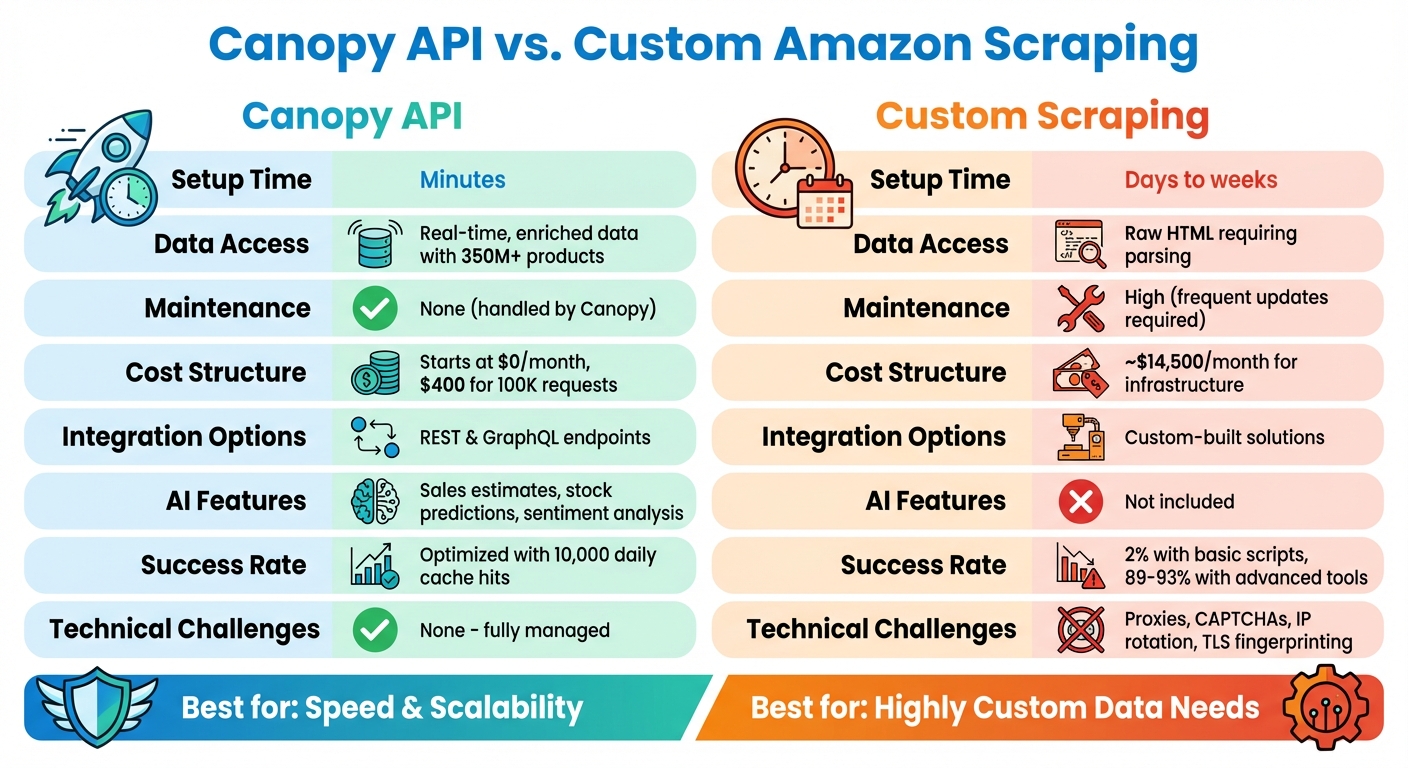
- Canopy API: Offers fast integration, real-time data, AI-powered insights (e.g., sales estimates), and scalable pricing starting at $0/month. Ideal for businesses wanting hassle-free access to Amazon data.
- Custom Scraping: Provides flexibility for niche data needs but requires managing proxies, CAPTCHAs, and constant updates. Costs can exceed $14,500/month for large-scale setups.
Quick Comparison:
| Feature | Canopy API | Custom Scraping |
|---|---|---|
| Setup Time | Minutes | Days to weeks |
| Data Access | Real-time, enriched data | Raw HTML requiring parsing |
| Maintenance | None (handled by Canopy) | High (frequent updates required) |
| Cost | Starts at $0; $400 for 100K requests | ~$14,500/month for infrastructure |
| Integration Options | REST, GraphQL | Custom-built |
| AI Features | Sales/stock estimates, sentiment | Not included |
If you prioritize speed, ease, and advanced features, Canopy API is the better choice. For highly specific data needs, custom scraping might work - but comes with steep costs and technical hurdles.
Canopy API vs Custom Amazon Scraping: Feature Comparison Chart
Canopy API: Features and Benefits
Real-Time Data Access
Canopy API provides real-time access to Amazon product data, including product titles, descriptions, pricing, sales estimates, and stock levels as they update on Amazon. You’ll always get the most current data.
The platform supports rapid responses with 10,000 daily cache hits. It also delivers enriched offer data for improved accuracy. Additionally, Canopy API tracks keyword rankings and category sales insights across a massive database of 350 million products spanning over 25,000 categories.
To make things even easier, the integration process is designed to be quick and straightforward.
Integration Simplicity
Getting started takes just a few steps: sign up, grab your API key, and choose between REST (https://rest.canopyapi.co/) or GraphQL (https://graphql.canopyapi.co/) endpoints using API-KEY or Bearer token authentication.
GraphQL is especially handy when you only need specific data points. For example, instead of retrieving an entire product dataset, you can request just the fields you need - like best seller rank or sales velocity. Canopy API also offers detailed documentation and open-source examples for Python, JavaScript (fetch), Apollo Server, and GraphQL Yoga, making integration with your development stack smooth and hassle-free.
Scalability and AI-Powered Insights
Canopy API grows with your business. It offers volume discounts at usage levels of 10,000 and 100,000 requests per month. For businesses with high data demands, the Premium plan starts at $400/month for 100,000 requests, with additional requests priced at $0.004 each. This pricing structure lowers costs as your usage increases.
But Canopy API isn’t just about raw data. It uses AI-powered processing to go beyond simple scraping. For instance, it can provide insights like review sentiment analysis and automated compliance checks. Developers building AI-driven applications will appreciate the Model Context Protocol (MCP) server, which connects real-time Amazon data to large language models like ChatGPT. This enables advanced workflows, such as automated repricing and in-depth analysis.
sbb-itb-d082ab0
Amazon Scraping Methods: Challenges and Approaches
Anti-Scraping Defenses
Amazon employs a sophisticated six-layer AI defense system, making traditional scraping methods significantly harder to execute. These defenses include IP reputation analysis, TLS fingerprinting (JA3/JA4), browser environment detection, behavioral biometrics, CAPTCHA challenges, and machine learning-based anomaly detection. As a result, basic Python scripts with rotating proxies now see a success rate as low as 2% against these measures.
One of the most advanced layers focuses on behavioral biometrics, analyzing factors like mouse movements, click timing, and scrolling speed to detect synthetic patterns that lack the natural variability of human users. Amazon also cross-references the HTTP User-Agent header with TLS handshake metadata to catch inconsistencies.
"Amazon compares your HTTP User-Agent header against your actual TLS fingerprint. If you claim to be Chrome 120 but your TLS handshake reveals Python's requests library, you're instantly blocked." - Pangolinfo
Amazon’s anti-bot system assigns a "human likelihood score" to each request, leveraging machine learning to flag suspicious behavior. Adding to the complexity, the platform frequently updates its front-end and uses different page templates across product categories, disrupting scrapers that rely on static selectors. These measures create a steep hurdle for those attempting to collect data without detection.
Custom Infrastructure Requirements
Building an in-house scraping setup to bypass Amazon's defenses demands a considerable investment, both in terms of money and expertise. Key components include residential proxy services (since data center IPs are quickly flagged), robust server infrastructure for parallel requests, and real-time monitoring systems. Such a setup can cost around $14,500 per month.
To evade TLS fingerprinting, specialized libraries like curl_cffi are necessary. Additionally, scrapers must be designed with advanced exception handling to adapt to Amazon’s frequent structural changes or manage network errors. Multi-threaded scrapers, while capable of operating up to 100 times faster than single-threaded ones, require careful engineering to avoid triggering rate limits.
"The golden rule: Always scrape in guest mode. Never use authenticated sessions for automated data collection." - Pangolinfo
Compliance with regulations like GDPR and CCPA is also critical, requiring systems to filter out any personally identifiable information (PII) before storing data. For businesses scraping under 15 million pages a month, commercial scraping APIs often provide a 10–15x better return on investment compared to maintaining a custom infrastructure. These complexities make API-based solutions a more practical choice for many.
Manual vs. Automated Scraping Tools
The challenges of building and maintaining a scraping infrastructure bring the debate between manual and automated tools into focus. Manual scraping, using libraries like BeautifulSoup or Selenium, demands constant upkeep. These tools only return raw HTML, which requires ongoing parser updates to handle issues like non-ASCII characters, unique URLs, and deeply nested data structures. Setting up and fine-tuning such systems can take days or even weeks.
Automated scraping tools, on the other hand, handle critical tasks like IP rotation, CAPTCHA solving, and browser fingerprinting internally. High-end services boast a 100% success rate on Amazon product pages, with response times ranging from 2,591ms to 3,223ms. They deliver structured JSON data with pre-parsed fields such as ASIN, price, ratings, and shipping details, eliminating the need for custom parsers.
Manual scrapers generally achieve success rates between 89% and 93%, meaning over 10% of your resources may be wasted on failed requests and retries. Automated services, by contrast, can scale to handle millions of requests daily without encountering bottlenecks, processing over 10 billion requests each month. These differences underscore the efficiency and reliability of automated tools for large-scale data collection projects.
Canopy API vs. Amazon Scraping: Direct Comparison
Data Retrieval Capabilities
Canopy API offers access to a robust Amazon product catalog, focusing on real-time data like product details, pricing, reviews, and even AI-driven metrics such as sales and stock estimates. It supports both REST and GraphQL interfaces, giving developers flexibility in how they interact with the platform.
On the other hand, traditional scraping methods gather raw data from product detail pages, variations (like size or color), search results, seller offers, and best-seller lists. While these methods can provide granular geo-targeting, they often make data extraction more complex.
Here's how the two approaches stack up:
| Feature | Canopy API | Traditional Scraping APIs |
|---|---|---|
| Primary Data | Real-time product details, pricing, reviews | Product detail pages, search results, seller offers, best-sellers |
| Unique Metrics | Sales estimates, stock estimations | Product variations (size/color), ZIP-level shipping |
| API Type | REST and GraphQL | Primarily REST |
| Success Rate | Not explicitly benchmarked | Provider dependent |
Ease of Integration and Maintenance
Canopy API simplifies integration, making it easy for developers to start pulling Amazon data in just minutes. It offers detailed documentation and open-source examples to speed up the process. Plus, Canopy handles the heavy lifting on the server side - managing proxies, solving CAPTCHAs, and rotating headers. When Amazon updates its site structure, Canopy automatically adjusts its endpoints (like the switch to OffersV2), saving users from manual fixes.
"Time is a precious resource, do not spend it maintaining your Amazon scraper, build your product!" – Canopy API
In contrast, traditional scraping demands more effort. Developers must manage proxies, set up parallel servers, and monitor systems in real time. Tools like BeautifulSoup or Selenium require constant maintenance, with initial setup and fine-tuning often taking days or weeks. Even automated scraping tools need tweaks when Amazon changes its endpoints.
Reliability and Scalability
Canopy API is built for reliability and scalability. It processes over 10,000 cache hits daily, optimizing response times while offering advanced insights like sales and stock estimates - data that’s tough to derive from basic scraping. By handling all updates to Amazon's structure, Canopy ensures developers can focus on building their products instead of maintaining scrapers.
Traditional scraping methods can deliver solid results but come with challenges. Enterprise-grade services rely on massive infrastructures, including over 150 million IPs across 195 countries, to avoid bottlenecks during large-scale data collection. However, performance can vary by provider, and lower success rates often mean implementing more robust retry systems for large datasets.
Scraping Data from Amazon using Scraping Browser API, ExpressJS & Angular
Cost Analysis and Pricing
When deciding between managed APIs and building custom infrastructure, understanding cost efficiency is crucial. Let’s break down the numbers.
Canopy API Pricing Plans
Canopy API offers flexible pricing options to fit different business needs:
- The Hobby plan is completely free, giving you 100 requests per month and email support. Perfect for small projects or testing the waters.
- The Pay As You Go plan starts at $0 per month, includes 100 free requests, and charges $0.01 per additional request. Plus, automatic volume discounts kick in at 10,000 and 100,000 requests, making it more economical as usage grows.
- For high-volume users, the Premium plan costs $400+ per month. It includes 100,000 requests, with extra requests billed at just $0.004 each - a 60% lower per-request cost compared to Pay As You Go. This plan also comes with premium phone support.
"Pricing that scales with you from side-project into a real business." – Canopy API
Cost of Scraping Infrastructure
Building your own scraping setup comes with a variety of costs. You’ll need:
- Proxies: Residential or mobile proxies to handle IP rotation.
- Servers: Reliable hosting to run scrapers at scale.
- Developer Time: Constant updates to your scrapers whenever platforms like Amazon change their structure.
The hidden cost? Opportunity cost. When developers are tied up managing parsers, proxies, and CAPTCHA challenges, they’re not focusing on your core product.
Total Cost of Ownership
The price difference becomes even clearer when you look at long-term usage:
- Low Volume (under 1,000 requests/month): Canopy’s Pay As You Go plan costs around $9 for 900 extra requests after the free 100. A custom setup, however, could cost $50 to $100 monthly for basic proxy services and initial developer setup.
- High Volume (100,000 requests/month): The Premium plan is $400, including 100,000 requests. A custom infrastructure could easily exceed $1,000 per month once you factor in proxy subscriptions, server hosting, and ongoing developer maintenance.
With Canopy API, you’re not just saving on manual upkeep. You’re also gaining access to advanced AI-powered insights, like sales and stock estimates, without needing to build additional models or logic. This makes it a streamlined, cost-effective choice for many business scenarios.
Use Case Recommendations
When to Choose Canopy API
If you need to move fast, Canopy API is a great option. Its REST and GraphQL endpoints come with detailed documentation and open-source examples, making it possible to integrate Amazon data in just minutes. This is especially useful when speed to market is a priority.
For teams that want to focus on their core product rather than dealing with the headaches of maintaining data scrapers, Canopy API offers a managed solution. Startups and small teams with limited developer resources will find this approach particularly helpful.
AI-driven applications can also gain a lot from Canopy API. With its MCP (Model Context Protocol) Server, it delivers real-time data directly to models like ChatGPT. This makes it easier to implement advanced workflows, such as automated repricing or detailed analysis. Features like Sales Estimates and Stock Estimations provide insights that are tough to calculate accurately using custom scrapers.
For businesses looking to scale, Canopy API offers flexible pricing tiers. Whether you're prototyping for free or handling high-volume enterprise needs, the pricing adjusts to match your growth.
That said, if your project requires extremely specific data not covered by standard API fields, you might need to consider other options.
When to Use Scraping Methods
Custom scraping is a better fit when your data needs go beyond what a standard API can offer. For example, if you're looking to extract niche details like ZIP-level shipping estimates or need over 600 custom attributes, a tailored scraping solution can provide the precision you're after.
For operations handling massive volumes of data on a tight budget, custom scraping might also be the more cost-effective route - assuming you have the engineering resources to support it. Managed scraping services generally cost between $0.10 and $1.50 per 1,000 requests, which is significantly less than the $4.00 to $10.00 per 1,000 requests associated with Canopy API. However, it's important to factor in the ongoing work required to maintain these scrapers. This includes managing proxy networks, dealing with anti-scraping measures, and updating parsers whenever Amazon updates its site structure.
Conclusion
Deciding between Canopy API and traditional scraping methods boils down to three main considerations: your technical resources, data needs, and ability to manage long-term maintenance.
As outlined earlier, Canopy API simplifies the process by delivering structured data in minutes through both REST and GraphQL endpoints. It eliminates the hassle of dealing with anti-scraping defenses and provides access to over 350 million products. Features like AI-powered sales estimates, which are hard to replicate with traditional methods, allow teams to concentrate on product development instead of infrastructure management.
On the other hand, traditional scraping methods can offer more flexibility with highly customized data extraction. If your project demands a wide variety of specialized fields and you have the engineering capacity to handle constant updates, this approach might work for you. But keep in mind, it comes with challenges like managing proxy networks, bypassing CAPTCHAs, and adapting to Amazon's frequent site changes.
Cost is another key factor. Canopy's Premium plan offers 100,000 requests for $400 per month, while maintaining a custom scraping setup requires continuous investment in engineering resources.
For most developers and e-commerce teams looking for a straightforward and scalable solution, Canopy API's free tier (100 requests per month) is an excellent starting point. You can scale up as your needs grow. Traditional scraping should only be considered when your data requirements go beyond what a standardized API can provide.
FAQs
What Amazon data can I pull with Canopy API?
Canopy API allows you to access a wide range of Amazon data, including product details like titles, descriptions, prices, and availability. You can also pull reviews, search results, sales estimates, and inventory status. For seamless data integration, it supports both REST and GraphQL endpoints.
When should I build my own Amazon scraper instead?
Building an Amazon scraper from scratch is usually only advisable in certain situations. Developing a custom scraper comes with hefty expenses - covering initial development, continuous upkeep, and potential legal hurdles. For most companies, opting for a dependable API, like Canopy's, is a smarter and more budget-friendly choice. That said, if you require highly tailored data extraction, complete control over the process, or are operating at a scale where API fees become too steep, creating your own scraper might make sense.
How do I estimate my monthly cost and request volume?
To figure out your monthly cost and request volume with the Canopy API, you'll need to factor in its pricing setup and your anticipated usage. Canopy provides a free tier that includes 100 requests per month. If you exceed that, pricing begins at $0.01 per request, or you can opt for larger plans starting at $400 per month.
For an estimate, multiply the number of requests you expect by the per-request rate, or consider if a flat-rate plan fits your needs better. Canopy's dashboard can help you track your usage and ensure you stay within your budget.